Use Data Points to extract information
Data Points allow you to improve search results by extracting specific product details from your indexed pages using XPath or CSS selectors.
How Data Points improve search:
- Search results become clearer by displaying essential product details like brand, stock status, and ratings in the results list.
- Users can sort products by attributes such as price, weight, or release date.
- Filters become more precise, allowing customers to refine their searches by color, material, brand or other important characteristics.
Create a Data Point
- Go to Search Studio > Data Structuring and click "Start now".
- In Data Structuring > Data Points, click "Add New Data Point" to open the setup template.
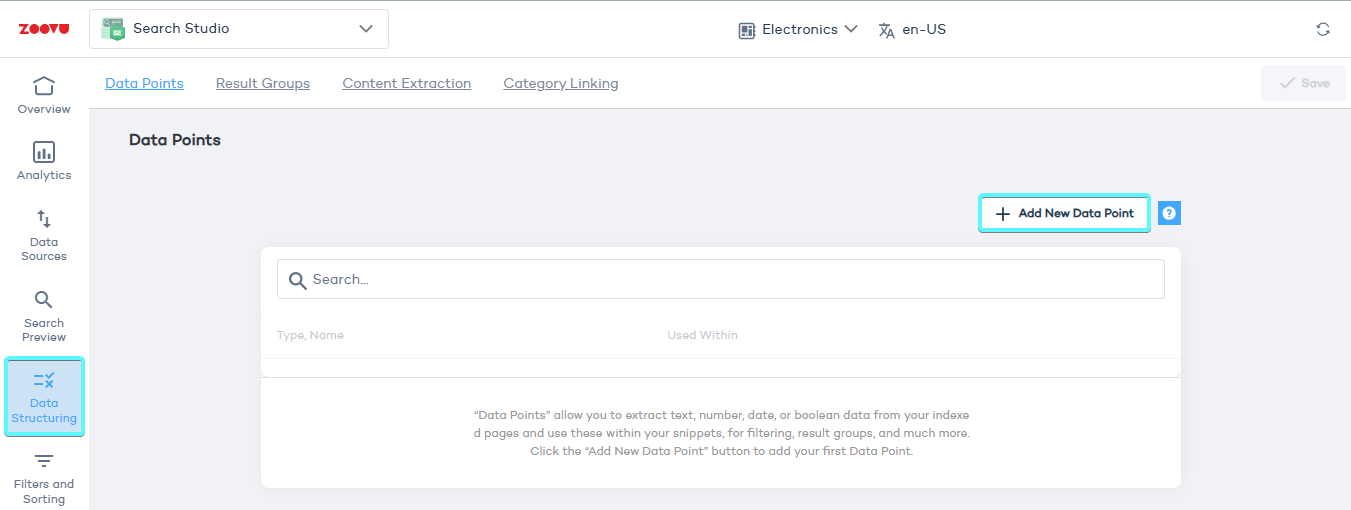
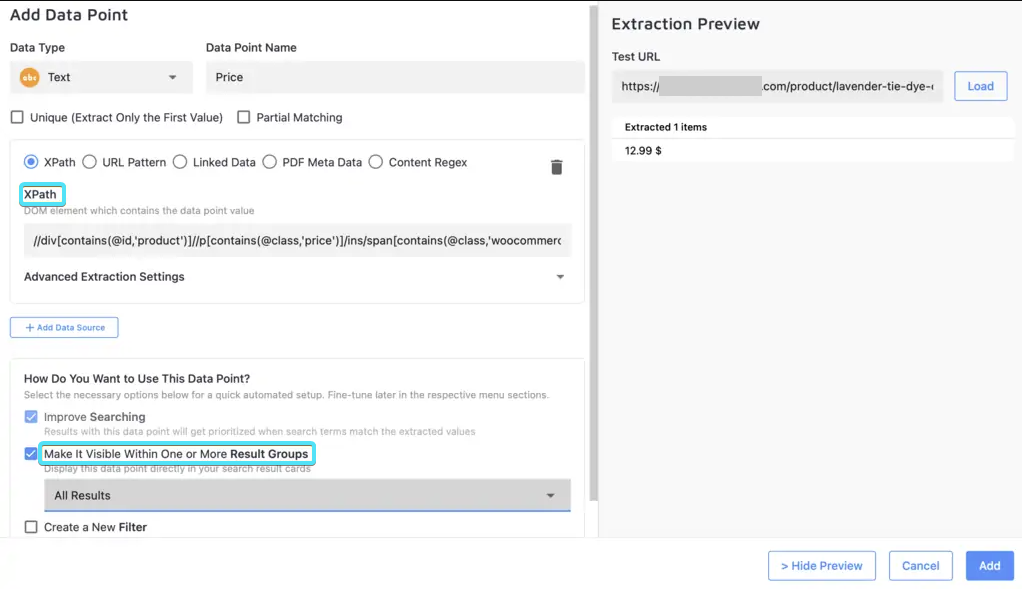
- Fill in the required details:
- name: define the data point’s name (e.g. "description" or "price")
- partial matching (optional) - to enable substring searches
- select data source like XPath or CSS selector to tell the crawler where to find the data
- Save your changes and re-index your site for them to take effect.
Methods for extracting Data Points
Data points can be extracted from different sources depending on how the information is structured on your website.
1. XPath (for structured page elements)
XPath (XML Path Language) is a way to navigate a website’s HTML structure to locate specific elements.
Best for: When product data (price, brand, SKU) is clearly structured in the HTML and follows a consistent pattern.
Example: Extracting a product price from a product page:
If the price is stored in this HTML tag:
<span class="product-price">$99.99</span>
The XPath expression to extract it would be:
//span[@class='product-price']
To find the correct XPath, use Chrome DevTools (Inspect Element) or an XPath helper extension like XPath Helper for Chrome.
2. CSS selectors (alternative to XPath)
CSS selectors allow you to target elements based on class names, IDs or attributes. They are an alternative to XPath for selecting data in HTML.
Best for: When product elements have unique class names and can be easily selected using CSS.
Example: Extracting a product name:
HTML Structure:
<h1 class="product-title">Cordless Drill 18V</h1>
CSS Selector:
h1.product-title
Use Chrome DevTools (Inspect Element) or extensions like SelectorGadget to quickly identify CSS selectors.
3. URL pattern (for extracting data from URLs)
Some product details are embedded in URLs rather than the page content. Regular expressions (regex) can extract these details.
Best for: When product categories, SKUs or other attributes are included in structured URLs.
Example: Extracting product category from a URL:
If a product page URL includes the category, a regex pattern can be used to extract it.
URL Structure:
https://mysite.com/power-tools/drills/cordless-drill-18v
Regex Pattern:
https:\/\/mysite\.com\/.*?\/(.*?)\/.*
Use online regex testers like regex101.com to validate and refine your expressions.
4. Linked data (for structured metadata extraction)
If your website uses JSON-LD or other structured data formats, you can extract product details from metadata.
Best for: Websites that use structured metadata, such as Google Merchant Center feeds or product schema markup.
Example: Extracting an SKU from a Product JSON-LD object:
A JSON-LD object contains structured data that can be accessed through key-value pairs. You can extract nested properties using slashes (e.g. brand/name to get the brand name).
JSON-LD Structure:
{
"@context": "https://schema.org/",
"@type": "Product",
"name": "Cordless Drill 18V",
"sku": "CDR-001",
"brand": {
"name": "ToolFactory"
}
}
Extracting brand name:
sku
brand/name
5. PDF metadata (for extracting properties from PDFs)
If your website includes product manuals or catalogs in PDF format, you can extract built-in metadata.
Extractable metadata fields:
- Author
- CreationDate
- Creator
- ModDate
- Producer
- Title
Extraction preview is not supported for PDFs, but you can test it by manually indexing a single PDF file.
6. Content regex (for pattern-based text extraction)
If product data is embedded within unstructured text, regular expressions (regex) can extract specific patterns.
Best for: Extracting structured data from unstructured product descriptions - model numbers, certifications or warranty periods.
Example: Extracting a model number from a product description:
Product description:
The ToolFactory Cordless Drill 18V (Model: CDR-001) is perfect for DIY projects.
Regex pattern:
Model:\s([A-Z0-9-]+)
Use regex tools like regex101.com to refine and test your expressions before applying them.
Using date and numeric Data Points in search
Date and numeric data points allow you to improve search results by adding structured information like publishing dates, prices, ratings or dimensions. These data points can then be used for sorting, filtering and enriching search snippets.
Date Data Points
Date data points are useful for sorting products based on time-related attributes, e.g. expiration date or last updated date.
Example: Sorting by product release date
If your website displays product release dates, you can extract and use this information in two ways:
- Sorting – Users can sort products by release date to see the newest items first.
- Search snippet display – The release date can be shown in search results under product details.
When defining a date data point, select the "Unique" option if you want to extract only one date per product.
Once the date data point is created, you can set it as the default sorting option, so search results automatically display the most recent products first.
Numeric Data Points
Numeric data points allow you to extract and use numbers for sorting, filtering, and ranking products. This can include price, rating, dimensions or stock levels.
Example: Extracting and using product price
If a product’s price is stored in the HTML, a numeric data point can extract it and automatically ignore currency symbols.
Once extracted, price data can be:
- Displayed in search results.
- Used for sorting (allowing users to sort by lowest to highest price).
- Used for filtering.
If multiple values exist for a single product (e.g., different sizes with different prices), deselect the "Unique" option to extract all available values.
Group search results using Data Points
Data points can also be used to group search results based on shared attributes.
Example: grouping electronics by brand**
If you have a data point for brand, you can group results so that all products from the same brand appear together.
To set this up:
- Use an existing data point or define a new XPath or URL pattern.
- Make sure the "Unique" option is deselected to capture multiple values (e.g., multiple features per product).
Showing data points in search suggestions
Data points can also appear in autocomplete suggestions, helping users refine their search before they hit "Enter".
Example: Displaying price and calories in search suggestions
If a search box suggests food products, you can display calories and price as extra details in the dropdown.
var ss360Config = {
suggestions: {
source: {
queryBased: {
content: [{
type: 'resultGroup',
dataPoints: [
{ key: 'Cost', type: 'value' },
{ key: 'Calories', type: 'chip' },
{ key: 'Protein', type: 'kv' },
]
}]
}
}
}
}
Display options for search suggestions:
value– Displays the value in plain text (e.g. "$19.99").chip– Displays the value inside a visual chip (e.g. "250 calories").kv– Displays both the key and value (e.g. "Protein: 3g").
Using data points via API
If you're sending data points via the Zoovu Search API, you can include them in the structuredData array for each uploaded page.
Each data point should include:
- A name (e.g. "Price" or "Publishing Date").
- A value corresponding to that page.
Example:
{
"url": "https://test.com",
"title": "My page title",
"content": "This is a test",
"structuredData": [
{
"key": "value"
},
{
"key": "Price",
"value": "$50"
}
],
"filters": [
{
"key": "value"
},
{
"tags": ["abc", "def"]
}
],
"language": "english"
}