Data Pipelines
Data Pipelines is an ETL (Extract, Transform, Load) tool in the Data Platform, which lets you connect and manage product data from different sources like CSV files, Google Sheets, or SAP systems. With ETL, you can automate importing, transforming, and exporting data.
Create a data pipeline
- To begin, go to the Pipelines tab in the left-hand menu.
- Click "Add pipeline" and enter a name and description.
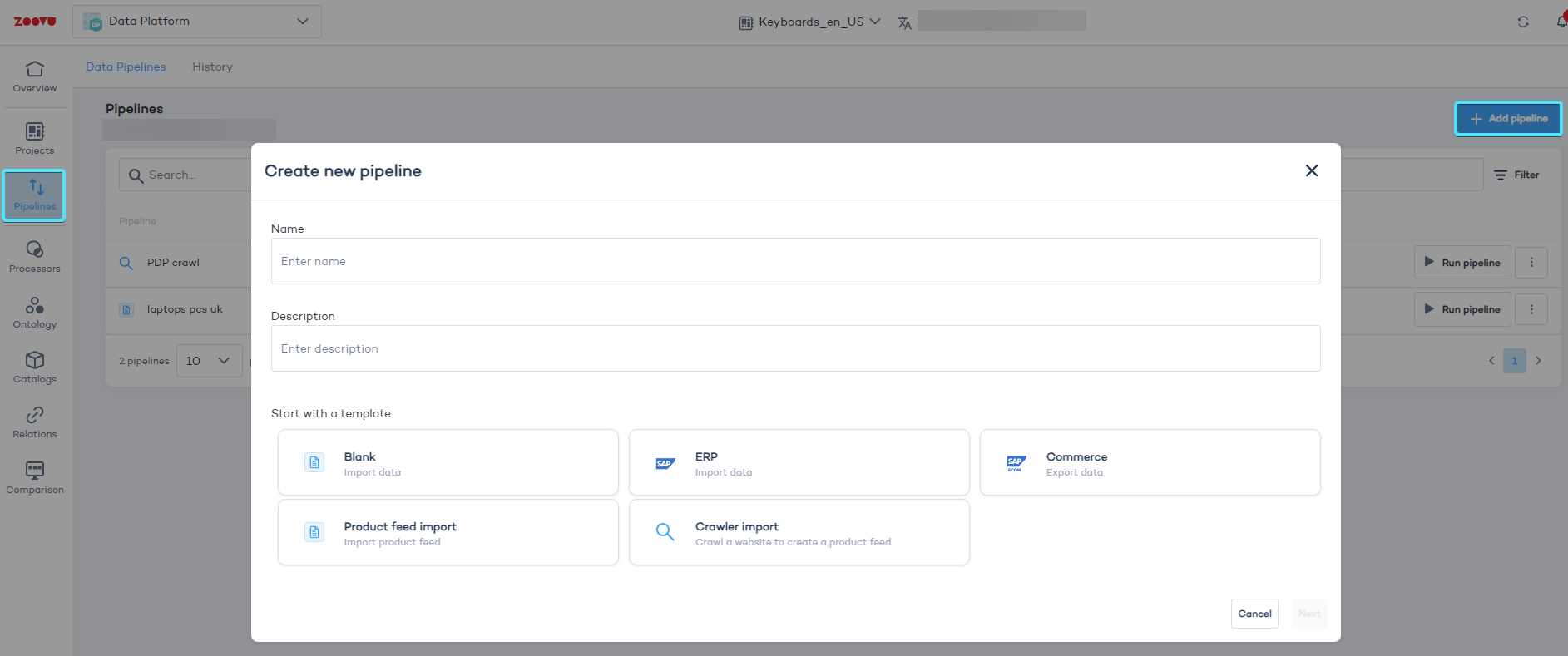
- Choose a template:
- Blank (Import data): Flexible, no predefined steps. Start with the Blank template for complex data or multiple sources.
- ERP (Import data) and Commerce (Export data): Useful for SAP users setting up data import/export processes.
- Product feed import: Use this to upload product data manually or schedule FTP uploads. Great for uploading CSV files from your computer or server (just make sure you have the right FTP credentials).
- Crawler import: Automatically create a product feed by extracting data from your website's content.
Set up tasks for managing your product data
When using the Blank template, you have full control over setting up each step in your data pipeline. Define how you want to handle your product data by creating tasks. Each task in the pipeline represents a specific action, such as uploading, downloading, or processing files.
To begin, click "Add first step" and choose the actions you need to perform.
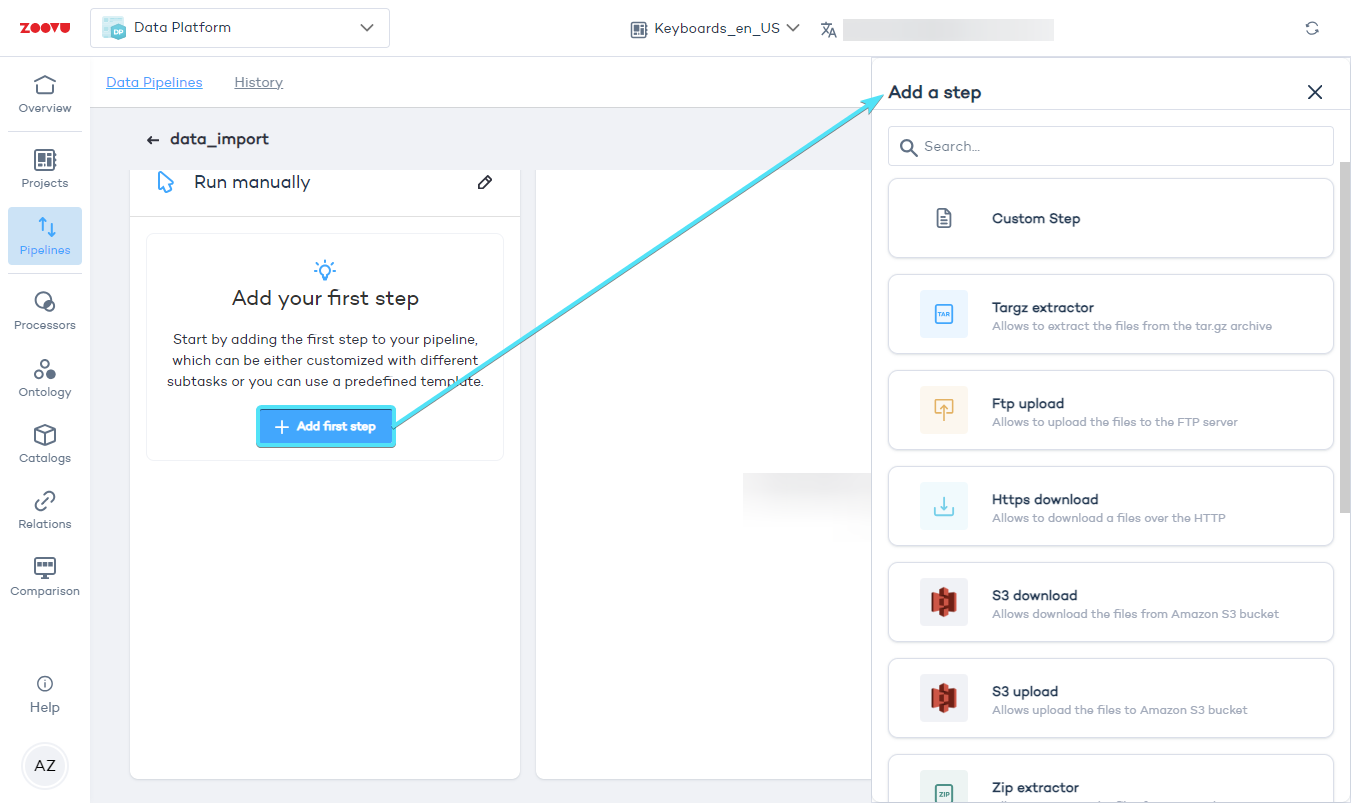
Here are some common tasks you might use:
- Targz extractor: Unpacks files from a
.tar.gzarchive. This is a compressed format used for packaging multiple files together, commonly used in Linux environments. - Ftp upload: Uploads files to an FTP server. Use this to send product data or processed files back to your server.
- Https download: Downloads files from a secure web link (HTTPS). This step is useful if your data is hosted online.
- S3 download/upload: Transfers files to or from Amazon S3 (Simple Storage Service).
- Zip extractor: Extracts files from a .zip archive.
- Remote file downloader: Automates the process of retrieving files from an FTP server, which is useful if your product data is regularly updated on external servers.
- Join/Union files: Combines multiple files into one, or merges the data from different files into a single dataset.
You can also create custom steps to control how your data is read, processed, or saved in the system with options like READER, PROCESSOR, or WRITER.
Saving and running your data pipeline
Once you’ve added and configured all your tasks, click Apply to save them. Then, click "Save & Run" to start processing the pipeline. You’ll receive a confirmation message once it’s running successfully.
If an error occurs, it’s usually due to incorrect FTP details, file paths, or network issues. Double-check your configuration and try again.
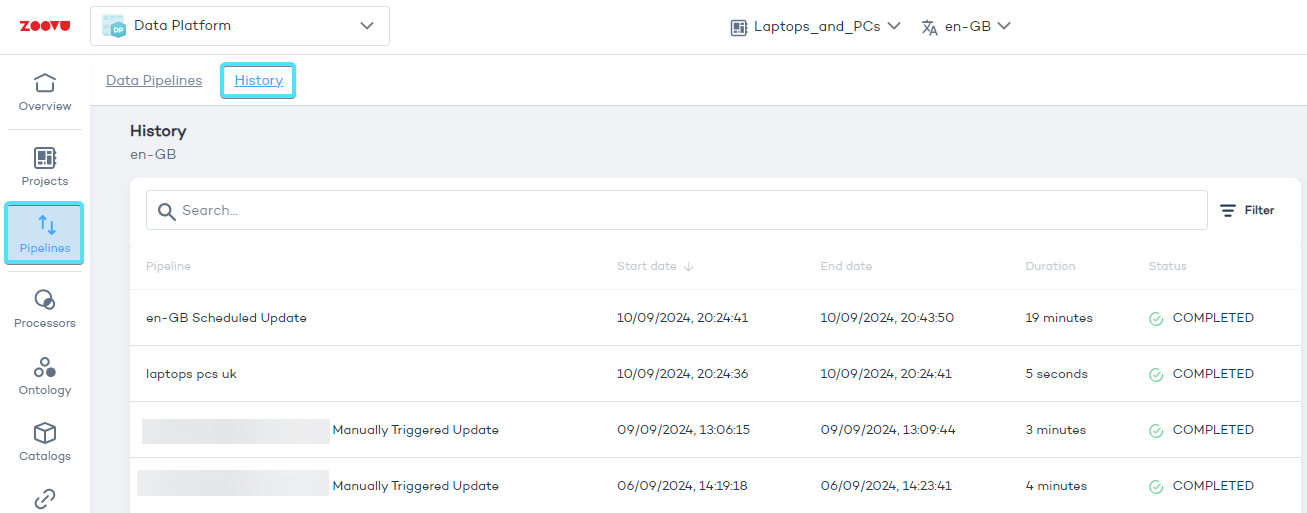
Monitor your data pipelines
To keep track of your pipeline’s progress and troubleshoot any issues, go to the History panel. Here, you can see the status of your pipeline and any error messages.