Crawl your website to import product data
The crawler in Data Platform alllows you to import product data directly from your website, sitemap, or specific URLs.
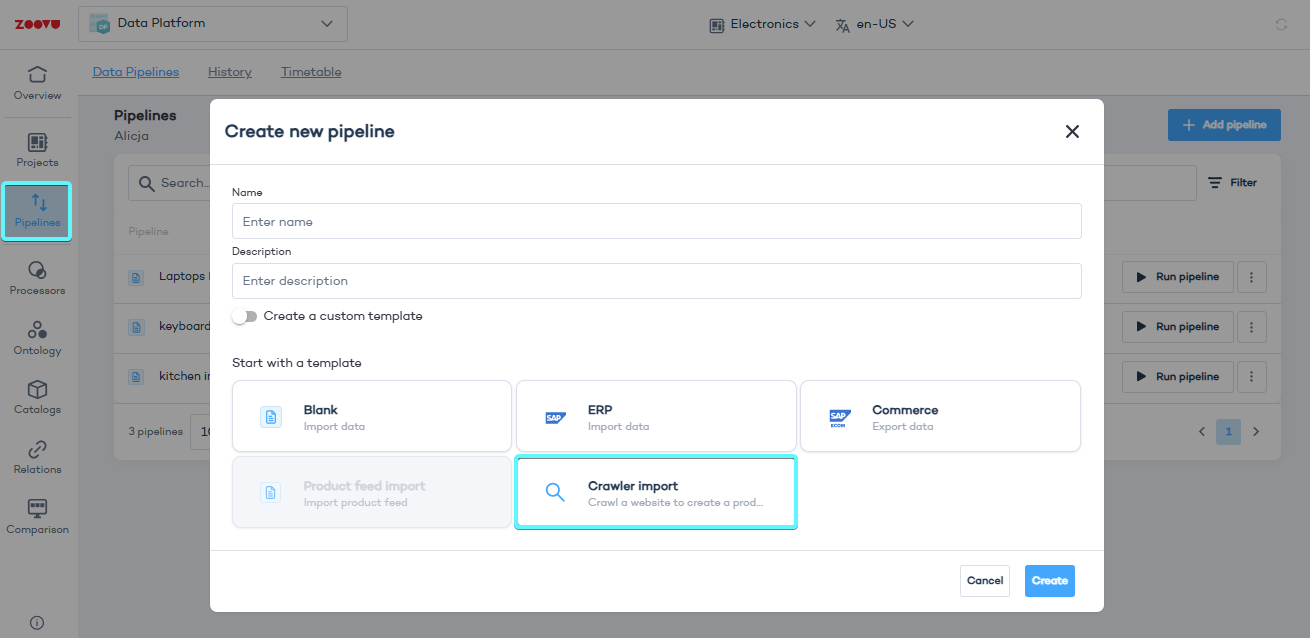
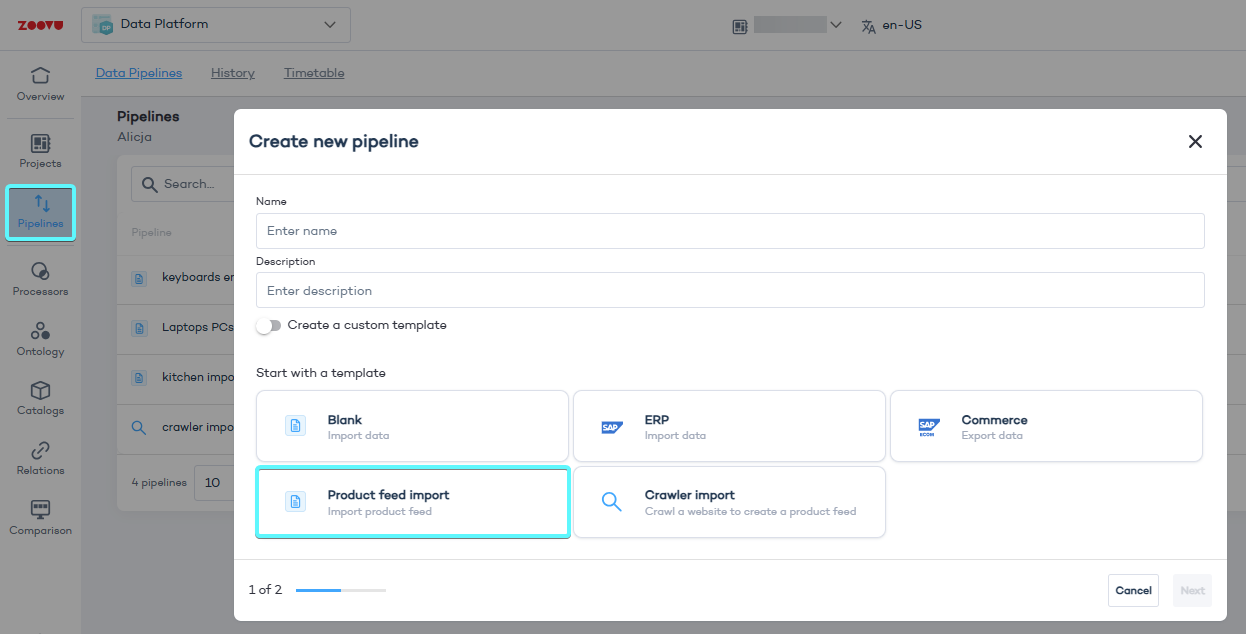
Step 1: Add a new crawler pipeline
- Go to Data Studio > Data Pipelines.
- Click Add pipeline, give it a name, and select Crawler Import.
Step 2: Select your data sources
You can use one or more of the following methods to gather data:
Crawling
- Enter root URLs - Add the base URLs where the crawler should start, e.g.
https://www.shop.net. It can be your homepage or specific directories.
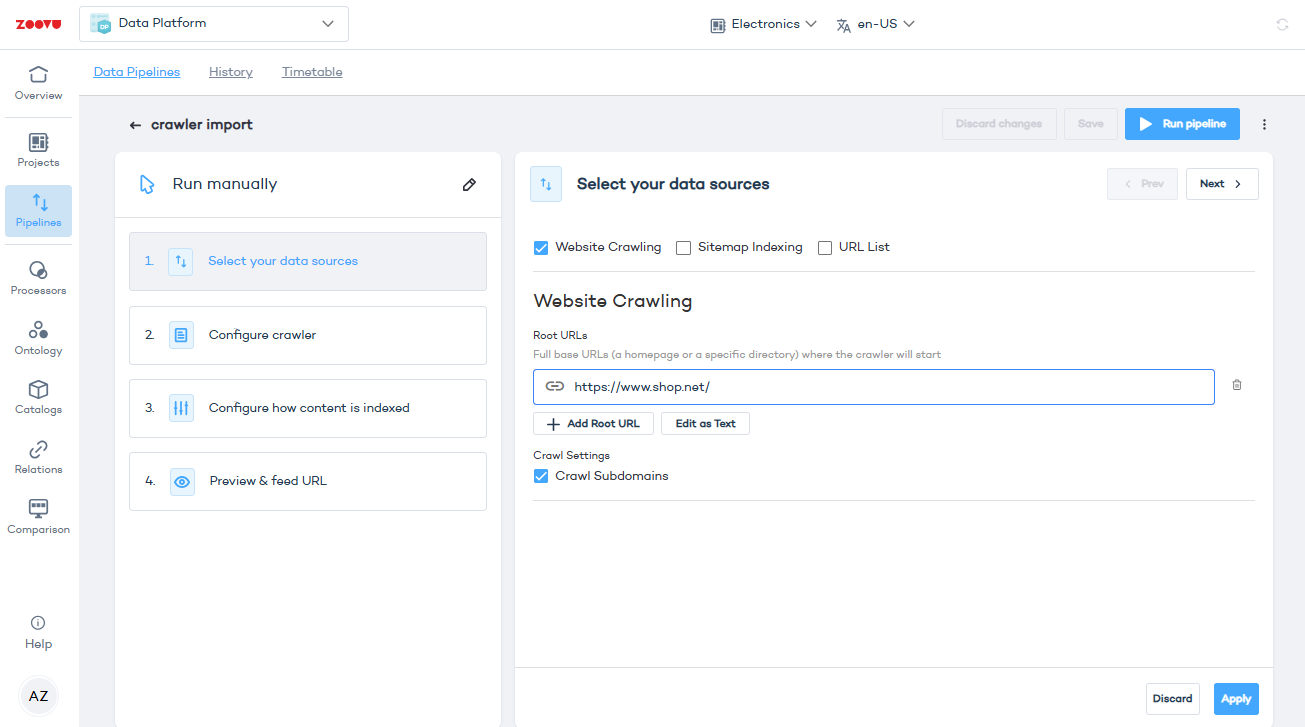
- Enable subdomain crawling - Check the "Crawl Subdomains" box if you want to include subdomains in the crawl.
- Click Apply to save.
If you encounter a 403 error, make sure that your website allows crawling (e.g., adjust permissions in your robots.txt file).
Sitemap indexing
Whenever possible, choose this option for importing your content into Data Platform.
Upload your sitemap to avoid additional crawling steps.
Use online sitemap finders if you're unsure of your sitemap's location.
Enter the sitemap URL, e.g. https://example.com/sitemap.xml.
Regular expression filtering
Include or exclude URLs using patterns. For example, .* matches everything.
Click "Test Sitemap" to verify the sitemap and indexed URLs.
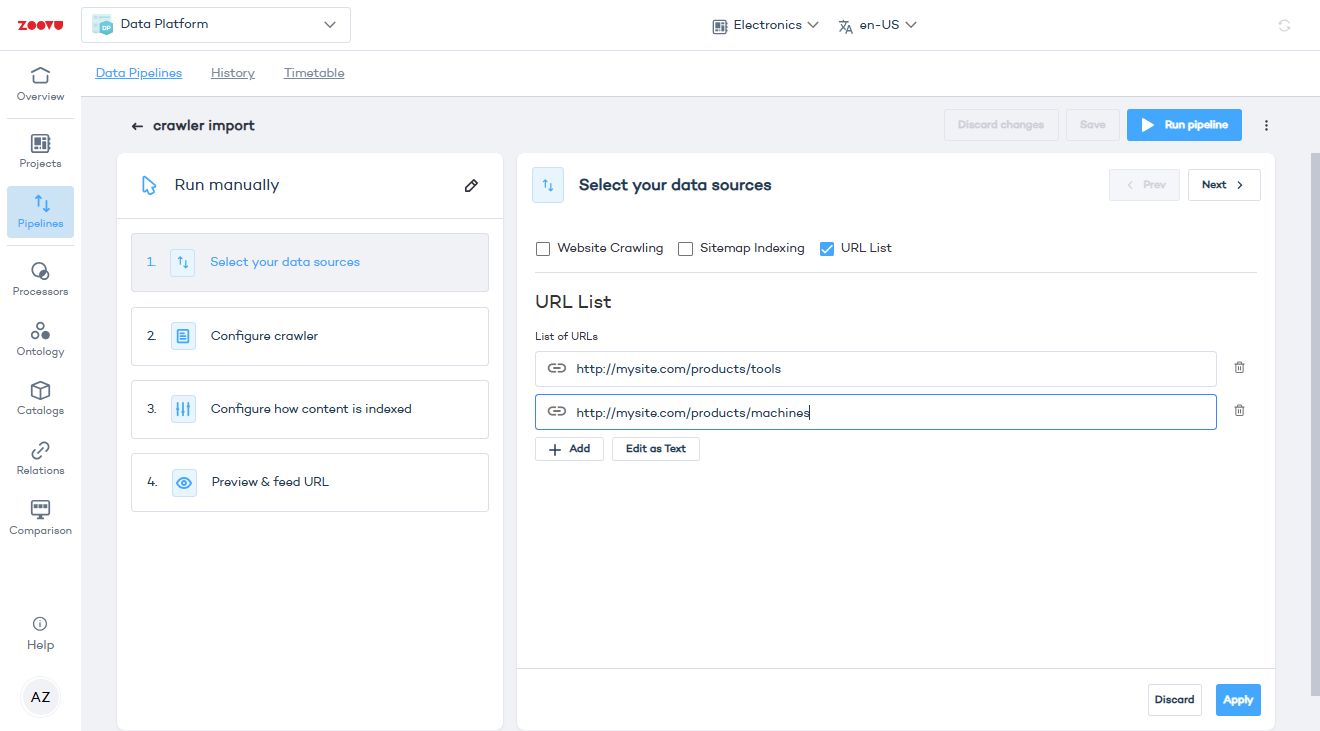
URL list
Provide a specific list of URLs to crawl in addition to general crawling or sitemap indexing.
Use this option for control over which pages are included.
Step 3: Configure crawler settings
To control which content gets indexed and appears in your search results, you can use blacklisting, whitelisting, and no-index rules.
Black- and whitelisting
Blacklist - Exclude URLs with specific patterns. Useful for excluding admin pages, private sections, or certain file types like PDFs.
- To exclude admin pages:
/admin/ - To ignore PDFs:
*.pdf
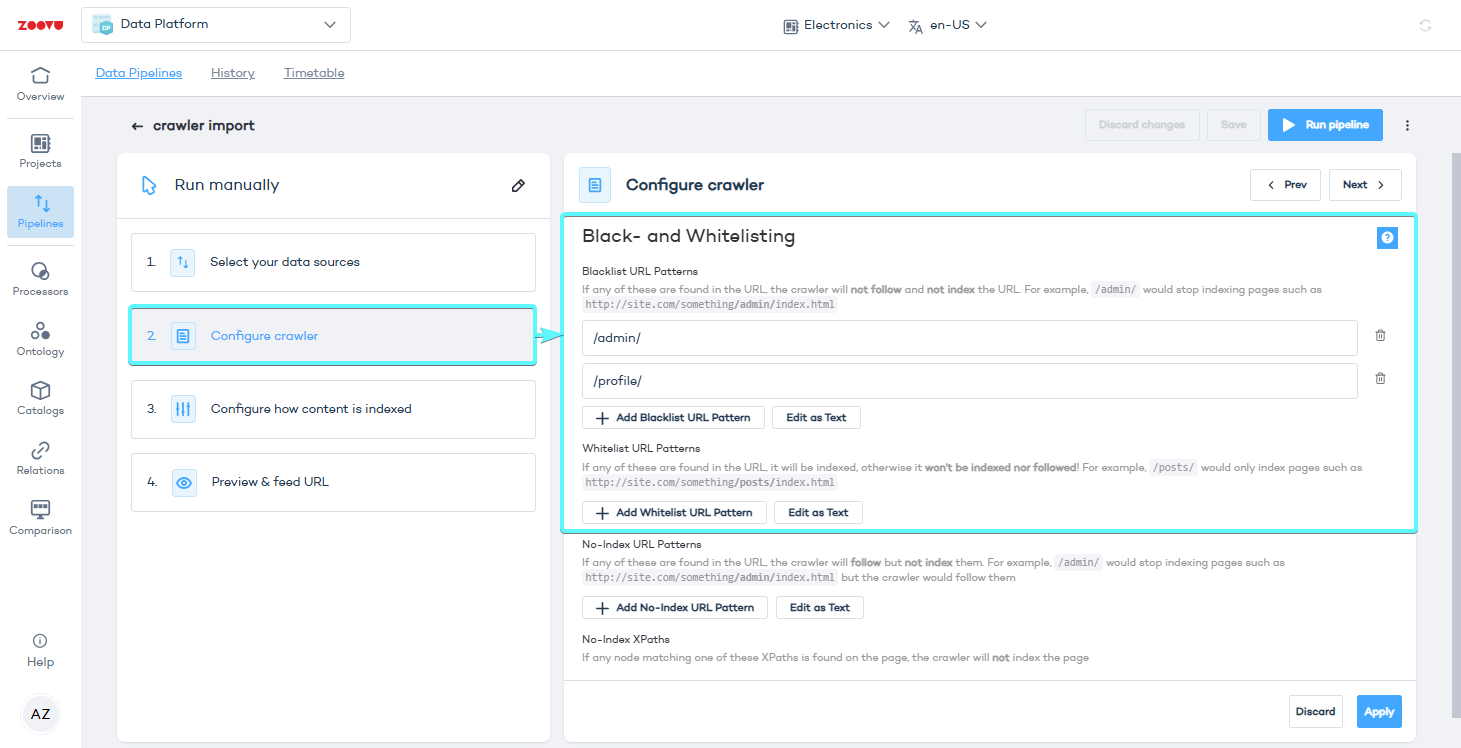
URL and XPath patterns are interpreted as regular expressions so remember to put a backslash \ before special characters, such as []\^$.|?*+(){}.
Whitelist - Only include URLs with specific patterns.
- To focus on blog posts:
/blog/ - To include only product pages:
/products/
Make sure that your root URL matches your whitelisting pattern (e.g. https://website.com/fr/). If the root URL doesn't contain the whitelist pattern, it will be blacklisted (which means nothing can be indexed, and there can be no search results).
No-index options
Prevent certain pages or elements from being indexed using patterns or XPaths.
- To exclude a landing page but follow its links:
/landing-page/
Set up no-index patterns for pages that should not be in your search results, but contain links to important pages. For example, you could exclude your blog landing page, but index all your blog posts.
No-index XPaths
Exclude pages that don’t share URL patterns. This lets you hide specific types of content that are identifiable by their structure rather than their URL.
- To exclude pages with a specific element:
//div[@class='hidden-content']
Authentication - Add login credentials for password-protected pages. Cookies - Set or disable cookies for specific behaviors (e.g., language selection). Indexing intensity - Adjust the balance between indexing speed and server load. Enable JavaScript crawler - Turn this on if your site relies on JavaScript for content rendering. Virtual page links - Allow the crawler to follow dropdowns or similar UI elements to gather product variants.
Step 4: Configure how content is indexed
- Title extraction - Define XPaths to extract product titles.
- Image extraction - Set up XPaths to pull product images.
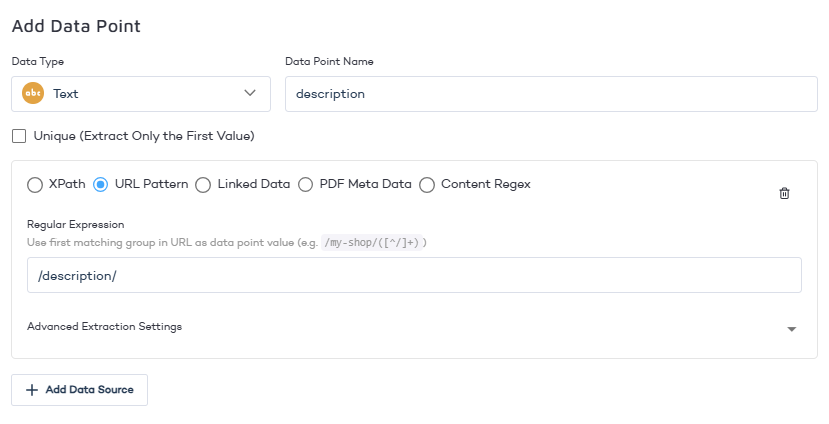
- Add new data point - Data points are reoccurring bits of information within your website's content, such as price, brand, SKU, number of items left in stock, etc. Use table data points to extract tabular data for filtering, grouping, or other catalog features.
Step 5: Preview and generate feed URL
Preview extraction - Test a URL to see the data the crawler extracts. Feed URL - Copy the crawler-generated CSV feed link. Example:
https://global.search.zoovu.com/data-export/crawl/cc88be5d-1a38-48ac-95c5-9c9fa7c68a1d.csv?projectId=43147&token=91v8t0sgbm5glhdtnfjqe89bft8q3l12
Step 6: Import the feed
- Create a new data pipeline in your project and select Product Feed Import.
- Import the CSV generated by the crawler.
- Use the imported data to build your product ontology, including attributes and values.
Tips and best practices
- Check for robots.txt files on your site—they may reference sitemaps to simplify crawler setup.
- Use the crawler preview tool to ensure you're extracting the correct data points.
- For analyzing data, use the Data Entries view in your catalog for a more streamlined experience.