Use XPaths to customize search results
XPaths are expressions that help you precisely identify elements on a web page. They are similar to CSS selectors but with more precision, especially useful when configuring search results. For example, the XPath //img will select all image elements on a page.
Configure XPaths for search
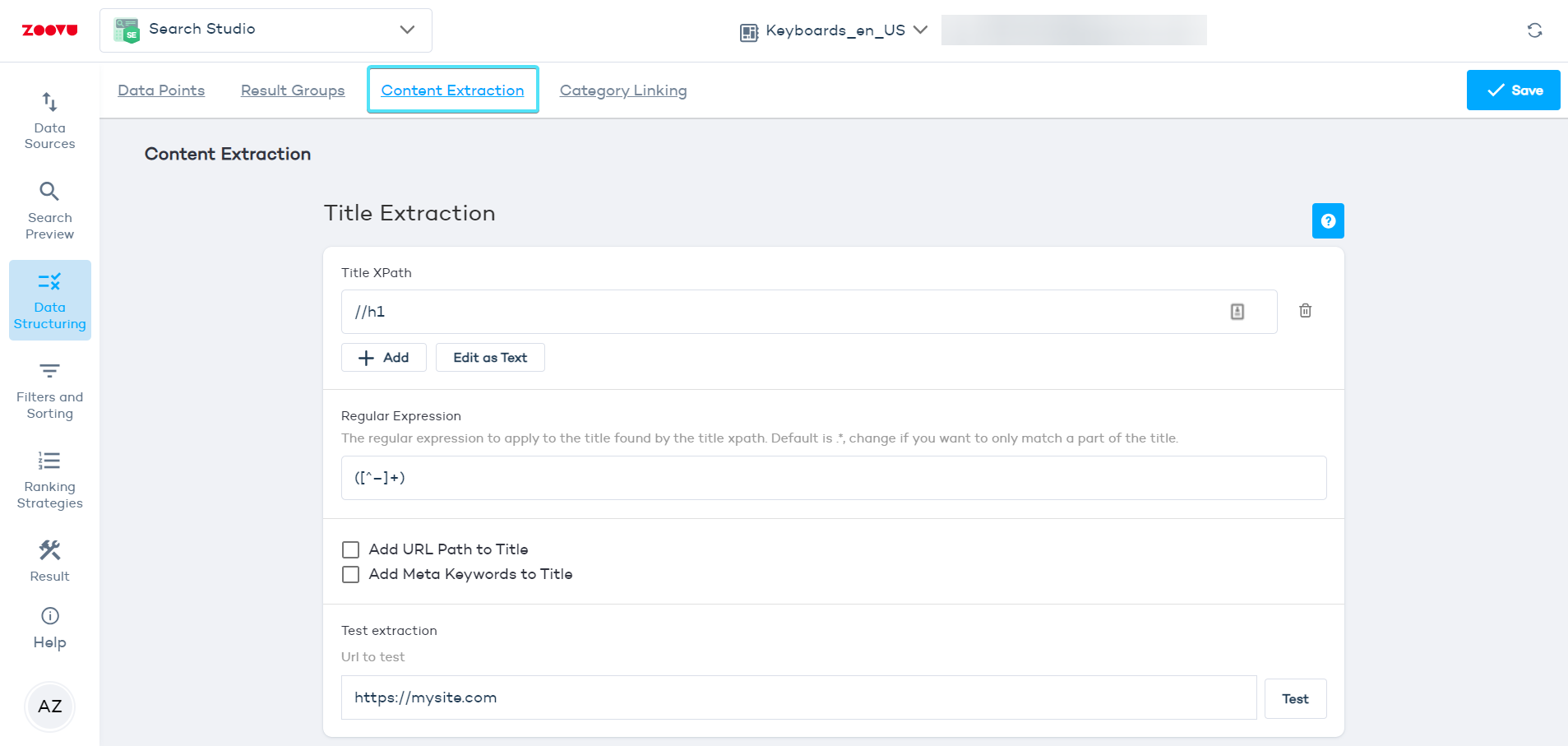
The Zoovu crawler can automatically select the best titles and images for your search results, but you can customize these by using XPaths in the Data Structuring > Content Extraction settings.
You can set up general rules in the Crawler settings, or create more specific rules in the Result Groups page if you're using Result Groups.
Find and test XPaths
To find and test XPaths on your site:
- Install XPath Helper - a Google Chrome extension.
- Go to the page you want to extract content from.
- Click the XPath Helper icon in Chrome to reveal the current XPath expression.
- Hold the Shift key and hover over the elements on your site. The XPath Helper will highlight them and display the corresponding XPath query.
- Simplify the XPath by shortening it. For example, you can remove everything before an ID element and start the XPath with //.
- Copy the XPath and paste it into the relevant section in Zoovu Search under Data Structuring -> Content Extraction.
Example:
- Original XPath:
/html/body[@id='body']/main/section[@class='u-pb-xxl u-pb-xl--sm']/article[@class='flex container'][1]/div[@class='main-feature__content col-6 col-12-sm'] - Shortened XPath:
//*[@id='body']//div[contains(@class,'main-feature__content')]
Test your XPath
- Copy your shortened XPath query.
- Navigate to Search Studio > Data Structuring > Content Extraction.
- Paste your XPath into the appropriate section (Title XPaths, Image XPaths, Include Content XPaths, or Exclude Content XPaths).
- Click the "Test" button and enter your webpage URL to see if the XPath works correctly.
If everything is correct, the extracted content, headline, or image URL will appear below the test field. You can also index a single URL to check what content will be extracted from that page.
Common XPaths for search results
Here are some typical use cases for XPaths in search results:
| XPath Type | Description |
|---|---|
| Title XPaths | Default is //h1. Adjust according to your site structure, e.g. by using //title to capture the page title. |
| Image XPaths | Default is often //img[@id='main']/@src. For lazy-loaded images, use something like //div[@class='product-detail-images']//img/@data-src. |
| Include content XPaths | Use to specify which content blocks should be indexed. |
| Exclude content XPaths | Use to tell the crawler which content blocks to ignore. |
| Search snippet XPath | By default, Zoovu shows content around the matching search terms. You can also use meta descriptions with //meta[@name="description"]/@content. |